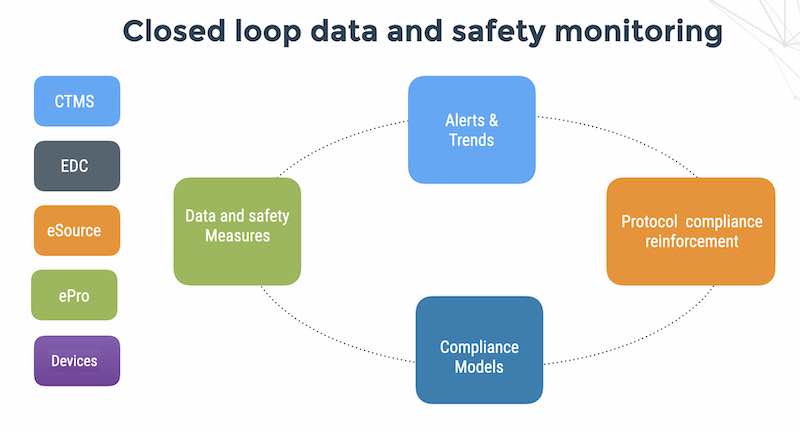
Another survey piece that David wrote about common mistakes in clinical data management and some basic controls to stay from the common issues.
Use automated monitoring to empower people
We are all human. As much as we would like to rely on technology to automate every sector of clinical trial research, we still need the human component to study, assess data, store it and make decisions based on captured research data. We cannot remove human study monitors and data managers entirely out of the equation.
That being said, many study sponsors are taking the initiative and advantage of the benefits of cloud EDC (electronic data capture) systems over the old-fashioned, paper-based method of data capture and management. Why? Because it is simply a cleaner method of data capture and saves study time.
The clinical trial field has changed significantly in recent years. In the past, the norm was for sites, monitors and data monitors to rely on paper source documents and SDV. Now, studies are increasingly becoming much more complex, often containing multiple study sites, larger numbers of patients, and measuring greater numbers of factors and variables and relying increasingly on cloud technologies to bridge the distance between the pharma and the sites
Enter cloud EDC and eSD (electronic source documents), which provides instantaneous access to study data across multiple sites, and at all times (you can even observe study data with your tablet or smartphone at home).
While cloud EDC is a boon for complex studies (and even simple, smaller studies, too), they do not perform the study for you. They are handy tools, but not cure-alls.
Despite how robust your cloud EDC may be, there are still human errors that can occur if proper care is not taken during the trial’s data management. Pressure is on in today’s fast-paced world for clinicians to be producing results that are accurate, reliable, and overall helpful for the biotech, medtech, pharmaceutical, etc. industries.
The two most common mistakes in clinical data management
Today, we are going to review the two most common mistakes that can happen during clinical research data management. Avoiding these mistakes will allow you to cut on study costs/time and run much more efficient clinical trials. Especially if you are running a large-scale clinical trial, this is invaluable advice on how to reduce human errors.
Contract research organizations (CROs) and study sponsors need to first be aware of how to curb inconsistencies in data entry, which is the bane of any clinical study.
1. Data entry inconsistencies
Inconsistencies between data in eCRF will happen if the data model is inconsistent (same field in 2 different forms) or if the naming is confusing and inconsistent (study termination date, time patient left study and similar naming ambiguities.
An additional root cause of data inconsistency is related to date typing where a data item may be defined in different ways – as string and as a date somewhere else.
To solve the problem, many sites adopt a system of centralized data management. To increase study productivity and cut on costs, many clinical trials may prefer the centralized approach for better control of study data, but this can also have its drawbacks. Errors may be reduced, with having greater access to oversight and data monitoring, but it requires more on-site personnel and takes much more time.
A well-defined data model implemented in Cloud EDC and use of eSource will resolve most of these issues as real-time edit checks will ensure proper typing and values for eCRF items,
2. Authorization errors & signature omissions
The second most common cause of data management mishandling is omission or neglect of trial master file signatures. These mistakes can either stem from simple oversight errors, or weak training of new study staff in charge of verification, but either way, during a clinical trial data’s integrity cannot be trusted if missing authorization.
Documentation needs to be organized and comprehensive, especially since that the FDA can audit your clinical trial throughout the study interval. Cloud EDC can assist in ensuring that whether or not you have chosen to use a centralized data management site or decentralized data collection that electronic signature fields are validated for submission to the study management team.
So, how do we prevent these issues from muddying your data management?
Less is more
Sponsors can be easily tempted to collect too much data on the assumption that there might be a use for the data at some point. However, a large collection of study data can slow down study performance.
So how do we minimize risks and allow for a cleaner, more relevant collection of study data?
When collecting your study data, follow these four simple rules to avoid the aforementioned previous two most common data management mistakes:
1. Identify, collect, monitor and manage data that is essential to the study design and end point and resist the temptation to collect more data just because you can,. Human errors are inevitable, and can be mitigated by collecting a small, focused data set as opposed to a large, confusing data set of variables
2. Data collection should be not only directed but standardized. Use your cloud EDC to ensure that a system is simple and in place for clinicians, whether new or seasoned are able to submit their data in a standardized format, saving time for monitor reviews.
3. Data edits and manipulation should be streamlined, allowing for even better organizational arrangement of clinical data management. As a rule of thumb, 6 edit checks per form is about right. More than that the CRC is working too hard.
4. Schedule same-day data capture, and quality assurance. Simply by entering the data while the patient is still there will be the best way of assuring that the data is valid.